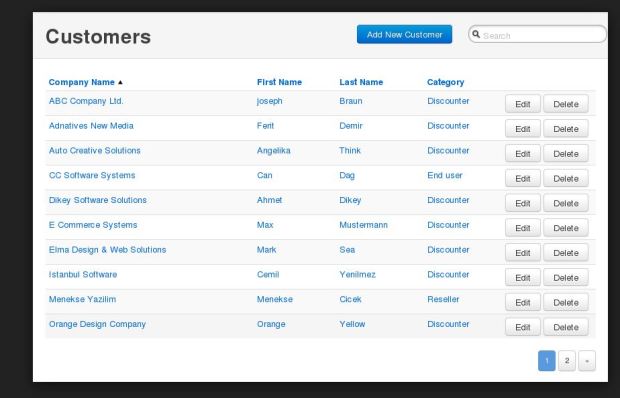
Pagination of query results for web application to show data by pages is a very common requirement across all types of application. Here is a solution to overcome certain common issues that we have today . The very popular solution in MySQL for this now a days is to use OFFSET and LIMIT with the select queries. The disadvantage with using OFFSET and LIMIT is each time when user request for a page, database engine process the entire data, sort it and calculate the particular page user asks for and return. In order to avoid this repeated full data process, we are doing a full data process first time , cache it and reuse the data. We also manage the cache to expire it appropriately.
We are going to achieve this using a search stored procedure and cache index table. The cache index table keeps the active sessions of cache.
create table paginationHdr (sessionid varchar(32),queryid int,temptable varchar(100),whereclause varchar(1000))
We keep the sessionid here to identify users session. Queries can be written inside using switch case , so that the procedure can be used for multiple queries. The best way is to keep this in a separate table so that we do not need to modify the procedure each time we insert a query. temptable field is nothing but the cache table name for the particular call.
Another thing is to keep in mind is that, when a web session expires, make sure you do the following things.
- drop all cache tables created for the expiring session ( Select temptable from paginationHdr where sessionid ='<session>’;)
- delete all records from the cache index table (paginationHdr) with the expiring sessionid
The procedure must be called as –
CALL spSearch(11,’12345678901234567890123456789012′,0,1,’ AND 1=1 ‘,’nameColumn’);
This stored procedure is implemented in MySQL but you can translate it pretty much to any relational database like SQL Server etc.
delimiter //
create procedure spSearch(p_queryid int, p_sessionid varchar (32),p_refresh bit,p_page int,p_whereclause varchar(1000),p_orderby varchar(100))
BEGIN
Set @v_pagesize = 3;
Set @v_basequery =null;
Set @s=null;
CASE p_queryid
WHEN 1 THEN
SET @v_basequery = ‘ SELECT idColumn,nameColumn, @curRank := @curRank + 1 AS rnk99, 0 AS pg99 FROM table1,(SELECT @curRank := 0) r WHERE active=1 ‘;
WHEN 2 THEN
SET @v_basequery = ‘ SELECT idColumn,nameColumn, @curRank := @curRank + 1 AS rnk99, 0 AS pg99 FROM table2,(SELECT @curRank := 0) r WHERE active=1 ‘;
END CASE;
Set @v_temptable=null;
SELECT temptable INTO @v_temptable FROM paginationHdr WHERE sessionid=p_sessionid AND 0=p_refresh AND queryid=p_queryid AND whereclause = p_whereclause;
IF @v_temptable is null THEN — This is for first time data pulling
Select CONCAT(‘TEMP’,SUBSTRING(MD5(RAND()) FROM 1 FOR 10),left(p_sessionid,5) ) into @v_temptable ;
LoopStart: LOOP
Set @tabletodelete=null;
Select temptable INTO @tabletodelete from paginationHdr Where sessionid=p_sessionid And queryid = p_queryid And whereclause=p_whereclause limit 1;
If @tabletodelete is null Then
leave LoopStart;
END IF;
SET @s = CONCAT(‘Drop table ‘ , @tabletodelete, ‘;’ );
PREPARE stmt FROM @s;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
Delete from paginationHdr Where sessionid=p_sessionid And queryid = p_queryid And whereclause=p_whereclause And temptable=@tabletodelete;
END Loop;
Insert into paginationHdr Values (p_sessionid,p_queryid,@v_temptable, p_whereclause) ;
SET @s = CONCAT(‘Create table ‘ , @v_temptable , @v_basequery ,p_whereclause,’ order by ‘,p_orderby,’;’ );
PREPARE stmt FROM @s;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @s = CONCAT(‘Update ‘ , @v_temptable , ‘ Set pg99= CASE WHEN MOD(rnk99,’,@v_pagesize,’)=0 Then rnk99 DIV ‘,@v_pagesize,’ WHEN MOD(rnk99,’,@v_pagesize,’) > 0 THEN rnk99 DIV ‘,@v_pagesize,’ +1 END ;’ );
PREPARE stmt FROM @s;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
SET @s = CONCAT(‘Select * from ‘ , @v_temptable , ‘ Where pg99=’ ,p_page,’;’ );
PREPARE stmt FROM @s;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END//